


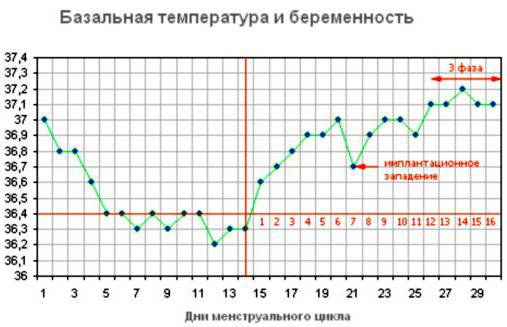


Если вы хотите, чтобы ваши дети были умными, читайте им сказки. Если вы хотите, чтобы они были более умными, читайте им больше сказок.
Альберт Эйнштейн






















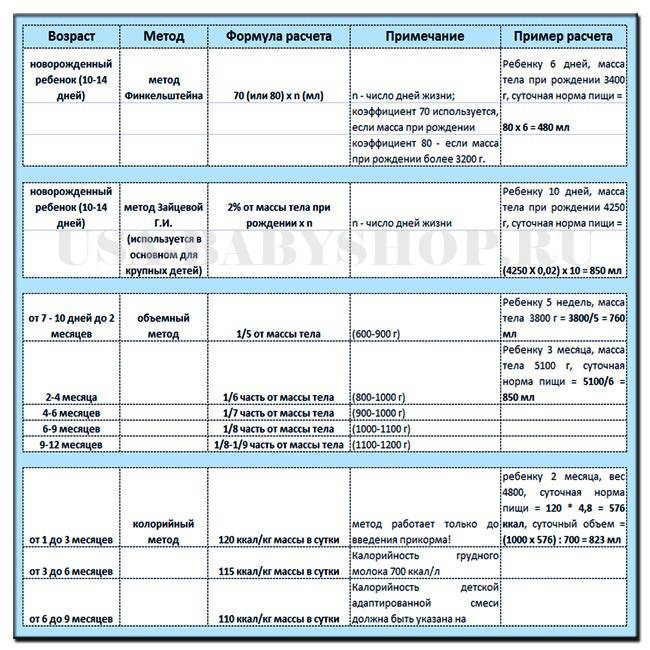















Если вы хотите, чтобы ваши дети были умными, читайте им сказки. Если вы хотите, чтобы они были более умными, читайте им больше сказок.
Альберт Эйнштейн




Сообщить об опечатке
Текст, который будет отправлен нашим редакторам: